
Hi. I'm Peter Bouda.
Building state-of-the-art Natural Language Processing
architectures.
The rest is LEGO.
Building state-of-the-art Natural Language Processing
architectures.
The rest is LEGO.

Text to Knowledge Graph project
for Regulatory Compliance Technology
#Spacy #NLP #SemanticWeb

Rasa chatbots and NLP
at a DAX company
#Rasa #Spacy #NLP #Python
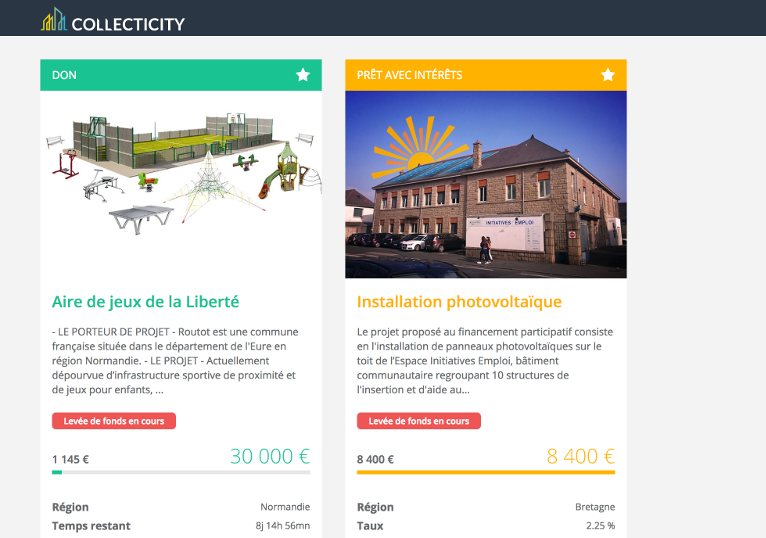
Full-stack JavaScript development
for a crowd-investment platform
#JavaScript #Angular #LoopBack

Open Source Technology
for Language Diversity.
#Python #Flask #NLP

Web-based interactive installation
by Stephan Jürgens.
#JavaScript #three.js

GUI- und Anwendungsentwicklung
mit Python und Qt.
#Python #PyQt
BrickBand was a follow-up of my Lego Coding idea, using bricks to create patterns for music.
This app is not available anymore, as Windows Phone was shut down.
Go to video...
Here is my talk “Poio Predictive Text - Grassroots Technology for Langage Diversity” at the Coding For Language Communities Devroom at FOSDEM 2020.
Go to video...
Watch Die Brummbeere in action. More info:
http://brummbeere.readthedocs.org/en/latest/
Go to video...
File "/data/home/pbouda/yolov3/utils/utils.py", line 45, in load_classes
names = f.read().split('\n')
File "/data/anaconda/envs/py35/lib/python3.5/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 157 …
You are hereby ordered to read:
Teach You Backwards: An In-Depth Study of Googe Translate for 103 Languages by Martin Benjamin
Read more...
This article was published on Hacker News today, a good overview and criticism of the current hype around NLP and speech-to-text in general. I like this comparison:
Read more...Stable production-grade NLP models usually are built upon data which is several orders of magnitude larger or the task at hand should be …